Java基础知识回顾--正则表达式
本文共 5935 字,大约阅读时间需要 19 分钟。
RegularExpressions
字符串处理利器正则表达式语法
正则表达式包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”)。 特殊字符 下表包含了单字符元字符的列表以及它们在正则表达式中的行为。 若要匹配这些特殊字符之一,必须首先转义字符,即,在字符前面加反斜杠字符 ()。 例如,若要搜索“+”文本字符,可使用表达式“+”。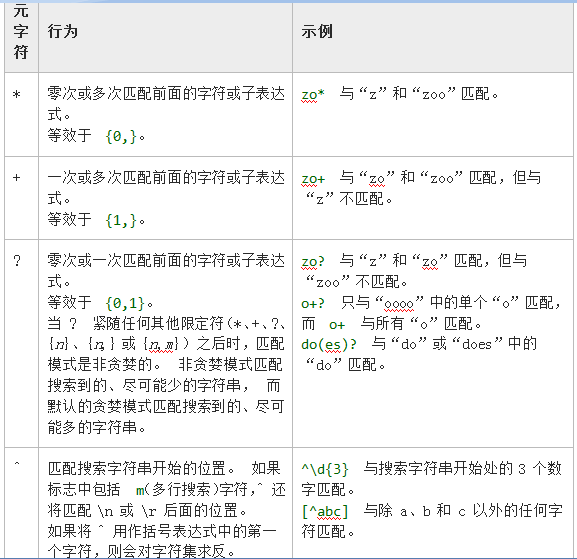
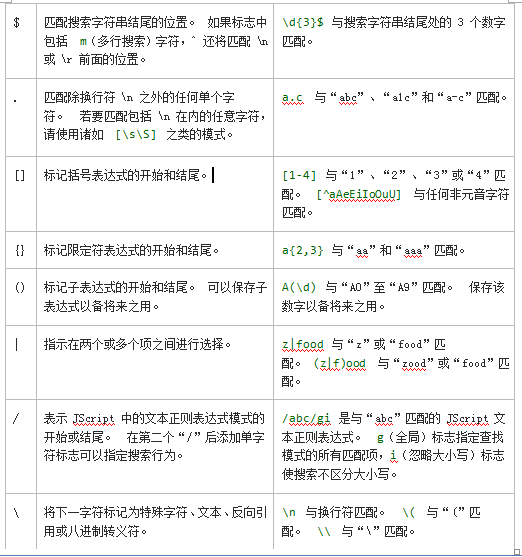
元字符
下表包含了多字符元字符的列表以及它们在正则表达式中的行为。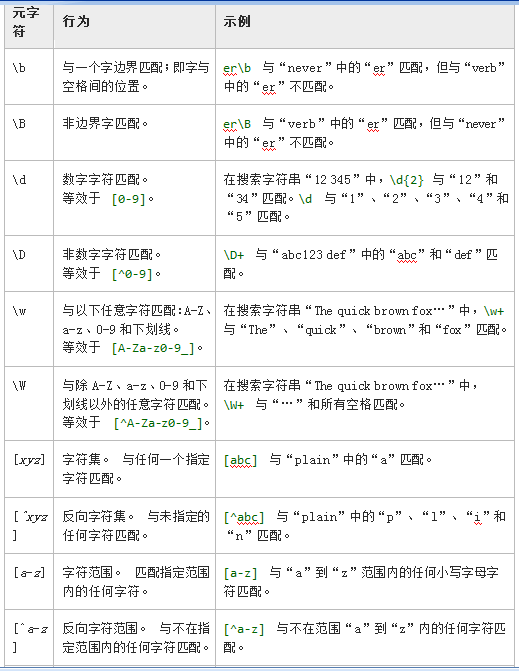
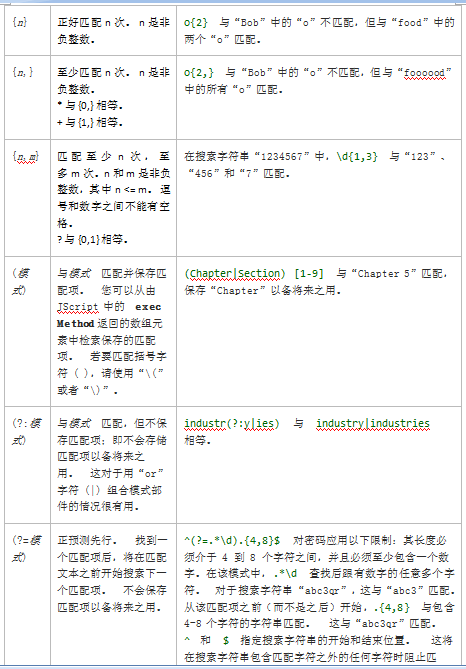
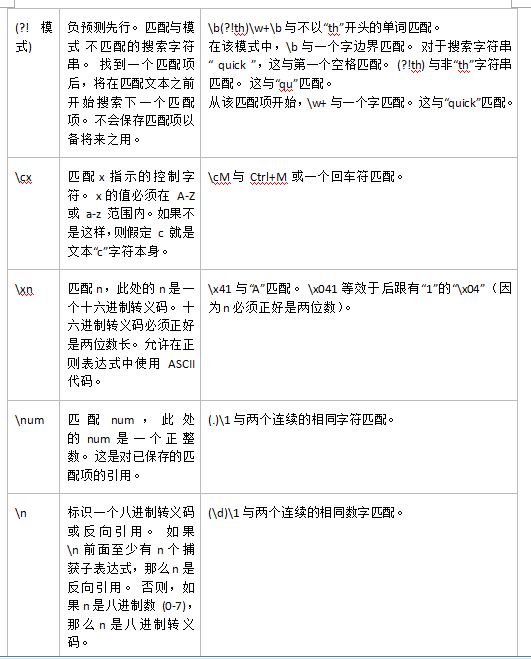

非打印字符
下表包含表示非打印字符的转义序列。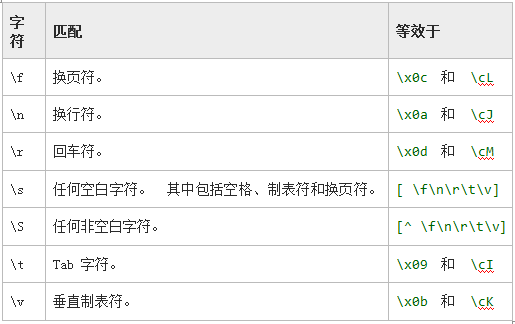
优先级顺序
正则表达式的计算方式与算术表达式非常类似;即从左到右进行计算,并遵循优先级顺序。 下表按从高到低的顺序包含了正则表达式运算符的优先级顺序。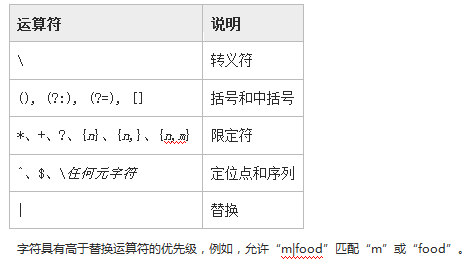
import java.util.regex.Matcher;import java.util.regex.Pattern;public class Test { public static void main(String[] args) { //简单认识正则表达式的概念 /* p("abc".matches("...")); //两个反斜杠d就是转义一个反斜杠d表示数字 p("a8729a".replaceAll("\\d", "-")); Pattern p = Pattern.compile("[a-z]{3}"); Matcher m = p.matcher("fgh"); p(m.matches()); p("fgha".matches("[a-z]{3}")); */ //初步认识. * + ? // * 零个或多个字符 // + 一个或多个字符 // ? 一个或零个 /* p("a".matches(".")); p("aa".matches("aa")); p("aaaa".matches("a*")); p("aaaa".matches("a+")); p("".matches("a*")); p("aaaa".matches("a?")); p("".matches("a?")); p("a".matches("a?")); p("214523145234532".matches("\\d{3,100}")); p("192.168.0.aaa".matches("\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}")); p("192".matches("[0-2][0-9][0-9]")); */ //范围 /* p("a".matches("[abc]")); //取非 p("a".matches("[^abc]")); p("A".matches("[a-zA-Z]")); //底下两种都是或者 p("A".matches("[a-z]|[A-Z]")); p("A".matches("[a-z[A-Z]]")); p("R".matches("[A-Z&&[RFG]]")); */ //认识\s \w \d \ /** * \s 所有的空白字符 * \w 小写a-z和A-Z和下划线_和0-9,构成关键字的字符 * \d 0-9 **/ /* p(" \n\r\t".matches("\\s{4}")); p(" ".matches("\\S")); p("a_8".matches("\\w{3}")); p("abc888&^%".matches("[a-z]{1,3}\\d+[&^#%]+")); p("\\".matches("\\\\")); */ //POSIX Style //p("a".matches("\\p{Lower}")); //boundary /** * 这个介绍看后面配图 **/ /* p("hello sir".matches("^h.*")); p("hello sir".matches(".*ir$")); p("hello sir".matches("^h[a-z]{1,3}o\\b.*")); //true,\b是单词边界 p("hellosir".matches("^h[a-z]{1,3}o\\b.*")); //false //whilte lines 空白行 p(" \n".matches("^[\\s&&[^\\n]]*\\n$")); p("aaa 8888c".matches(".*\\d{4}.")); p("aaa 8888c".matches(".*\\b\\d{4}.")); p("aaa8888c".matches(".*\\d{4}.")); p("aaa8888c".matches(".*\\b\\d{4}.")); */ //email //p("asdfasdfsafsf@dsdfsdf.com".matches("[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+")); //matches find lookingAt /* Pattern p = Pattern.compile("\\d{3,5}"); String s = "123-34345-234-00"; Matcher m = p.matcher(s); p(m.matches()); m.reset(); p(m.find()); p(m.start() + "-" + m.end()); p(m.find()); p(m.start() + "-" + m.end()); p(m.find()); p(m.start() + "-" + m.end()); p(m.find()); //p(m.start() + "-" + m.end());找不到用这个就会报错 p(m.lookingAt()); //每次都从头开始找起 p(m.lookingAt()); p(m.lookingAt()); p(m.lookingAt()); */ //replacement /* Pattern p = Pattern.compile("java", Pattern.CASE_INSENSITIVE); Matcher m = p.matcher("java Java JAVa JaVa IloveJAVA you hateJava afasdfasdf"); StringBuffer buf = new StringBuffer(); int i=0; while(m.find()) { i++; if(i%2 == 0) { m.appendReplacement(buf, "java"); } else { m.appendReplacement(buf, "JAVA"); } } m.appendTail(buf); p(buf); */ //group /* Pattern p = Pattern.compile("(\\d{3,5})([a-z]{2})"); //这个中间的两个小括号就是分组用的,分为两组 String s = "123aa-34345bb-234cc-00"; Matcher m = p.matcher(s); while(m.find()) { //p(m.group()); p(m.group(1)); //分组输出,正则表达式中小括号分组 } */ //qulifiers 修订词 /* Pattern p = Pattern.compile(".{3,10}+[0-9]"); //一下子吞最大的10个,然后发现不匹配吐出一个匹配 //Pattern p = Pattern.compile(".{3,10}?[0-9]"); //这个加问号的就是不贪婪的,只读最少的就是aaaa5 String s = "aaaa5bbbb68"; Matcher m = p.matcher(s); if(m.find()) p(m.start() + "-" + m.end()); else p("not match!"); */ //non-capturing groups 用得比较少,用的时候试一下 /* Pattern p = Pattern.compile(".{3}(?=a)"); String s = "444a66b"; Matcher m = p.matcher(s); while(m.find()) { p(m.group()); } */ //back refenrences 向前引用 /* Pattern p = Pattern.compile("(\\d(\\d))\\2"); String s = "122"; Matcher m = p.matcher(s); p(m.matches()); */ //flags的简写 //Pattern p = Pattern.compile("java", Pattern.CASE_INSENSITIVE); p("Java".matches("(?i)(java)")); } public static void p(Object o) { System.out.println(o); }} 上述代码又看不懂的这有图片解释


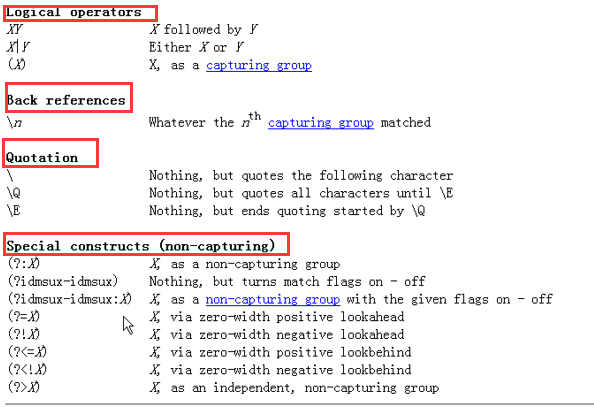
下面贴出网页中抓取邮件的小例子。
import java.io.BufferedReader;import java.io.FileNotFoundException;import java.io.FileReader;import java.io.IOException;import java.util.regex.Matcher;import java.util.regex.Pattern;public class EmailSpider { public static void main(String[] args) { try { BufferedReader br = new BufferedReader(new FileReader("D:\\share\\courseware\\1043633.html")); String line = ""; while((line=br.readLine()) != null) { parse(line); } } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } private static void parse(String line) { Pattern p = Pattern.compile("[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+"); Matcher m = p.matcher(line); while(m.find()) { System.out.println(m.group()); } }}
你可能感兴趣的文章
外嫁美的被指违约 东芝创维合作或重谈
查看>>
HCI的全面升温可能导致软件定义型传统阵列遭遇搁浅
查看>>
特斯拉和SolarCity下月召开特别股东大会 表决合并事宜
查看>>
Denyhosts shell script
查看>>
高清摄像机镜头的质量和价格分析
查看>>
中国移动计划牵头推动5G传输国际标准立项
查看>>
苹果补上了可被未授权收集传感器数据的iPhone漏洞
查看>>
《UNIXLinux程序设计教程》一2.6 文件结束和错误指示器
查看>>
Q3全球太阳能企业融资规模达30亿美元 环增76%
查看>>
华为4.5G助力TDC创造丹麦移动网络峰值速率新纪录
查看>>
融合系统的前景如何?
查看>>
科达教育行业解决方案发布会在广州举行
查看>>
15张图表,一览数字健康的热闹和门道
查看>>
在精准医疗的风口,医院、医保、互联网医疗如何顺势而为?
查看>>
全球首个5G全息国际视频通话打通
查看>>
警惕:未得到Oracle许可的应用程序存在风险
查看>>
政策有变,“晚婚假病毒”借机来袭
查看>>
ICTroom公司优化其模块化数据中心的容量
查看>>
说一说数据中心里的那些线
查看>>
工信部:继续推动绿色数据中心建设
查看>>